
 �D6����׃����ֵ�˺�
�D6����׃����ֵ�˺�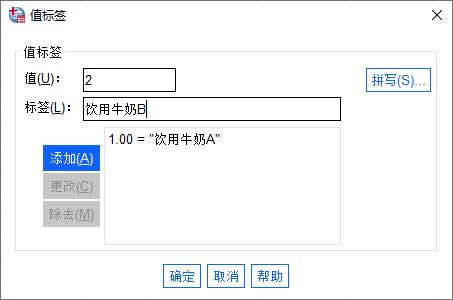
 �D8����ɘ˺��O��
�D8����ɘ˺��O��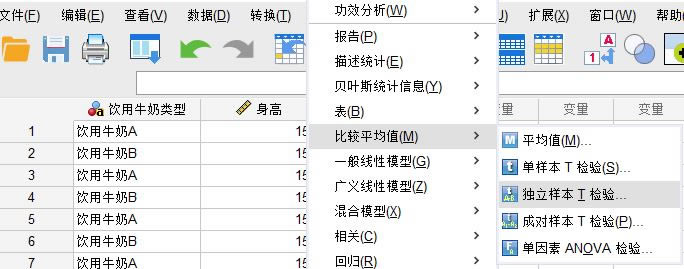
 �D6���Y�����@��
�D6���Y�����@��- SPSS���ָ���^�ַ���֮�x��
- SPSS�ә������đ��ý�B
- ��Α���SPSSӋ����׃�����ɣ��ھ��¶���
- ��Α���SPSS������ֵ��Ӌ������
- SPSS���¾��a֮���a����ͬ��ͬ��׃��
- ��Α���SPSS�l�ʅ^�֣�SPSS�^�֔�ֵ��
- ��Α���SPSS̽���ԅ^�֣�SPSSѸ�ٙz��
- ��Α���SPSS̽���ԅ^�֣�SPSS�z��
- ��Α���SPSS����^��_SPSS̽��׃��
- ��Α���SPSSƽ��ֵ�z�_SPSS̽����Ⱥ
- ��Α���SPSS�䌦�ӱ�T�zSPSS̽��
- ����\��SPSS�����z�_SPSS�z����

���ͨ�^SPSS�����ӱ�T�z�^�փɽM�����IJ
�l���r�g:2025-05-04 ����Դ:xp���dվ �g�[:
| SPSS��IBM��˾��Ʒ�����ṩ�˰��������ԽyӋ���Ɣ��ԽyӋ�����ӷ�������������ؚw�����ȶ�N�yӋ�������ܣ��������ı��������C���W���㷨����������ģ�͵ȡ�SPSS�Ľ����Ѻã����ڲ������܉���ُĔ�������ȡ���õĶ���ͷ������V�������ڽ������������t�W���Ј����˿ڡ����U�ȶ����о��I��Ҳ���ڮaƷ�|�����ơ����n���������ճ��yӋ����ȡ� �����ӱ�T�z��cƽ��ֵ�z�Θӱ�T�z�䌦�ӱ�T�z�����ڱ��^ƽ��ֵ�ęz������ͬ���ǣ������ӱ�T�z���^���ǃɽM������ƽ��ֵ��ԓ�z���Ҫ�����S�C�ֲ��ļٶ���Ҳ�����f���ɽM���������g�IJ�o�����˞��Ӱ����ء� ��Ҫע����ǣ�“�����ӱ�T�z�”�z���ǃɽM�����������ǃɂ�׃���������Ҫ���������M���������⣬��ֽM׃�����Ô�ֵ���R���@���c��IBM SPSS Statisticsܛ�������������ע�⡣ һ�����_�����ļ� �����әz�������ţ��A�M�c���ţ��B�M�ij���������ƽ��ֵ�Ƿ����@���Բ�� ��D1��ʾ��ʾ������չ�F�������ţ��A�c���ţ��B�ɂ������M�����ߔ���������ʹ�õĔ����ǃɂ�׃����׃���M���������������ţ��A�c���ţ��B�ɂ�׃���Ĕ���������ͨ�^��׃�������D�Q�邀������������M�к��m������ ����һ���棬ʾ�������е����ţ�����׃��ʹ�õ����ַ���ֵ���҂���Ҫ�Ȍ��ַ����D�Q�锵ֵ�������M�Ъ����ӱ�T�z
�D1��ʾ������ ���������ţ�����׃�����¾��a ��D2��ʾ�����_IBM SPSS Statistics�D�Q�ˆ��е�“���¾��a�鲻ͬ׃��”��
�D2�����¾��a�鲻ͬ׃�� Ȼ����D3��ʾ������Ҫ���¾��a��“���ţ�����”׃�����ӵ��҂�ݔ��׃�������У��������Qݔ����О���������“���ţ����;��a”�� �������Γ�“�fֵ����ֵ”���o��ƥ���fֵ�c��ֵ��
�D3���O��ݔ��׃�� ��D4��ʾ�����fֵ�c��ֵƥ������У��քe�����ţ��A�����ţ��B�c��ֵ1��2��ƥ�䡣
�D4��ƥ���fֵ�c��ֵ ���׃�������¾��a���ؔ���������D5��ʾ�������г��F���µ�׃��—���ţ����;��a��
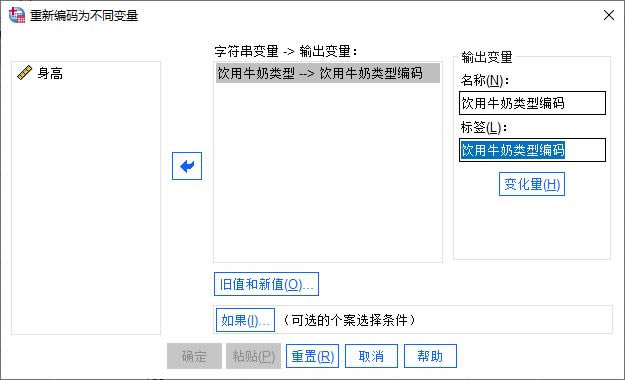
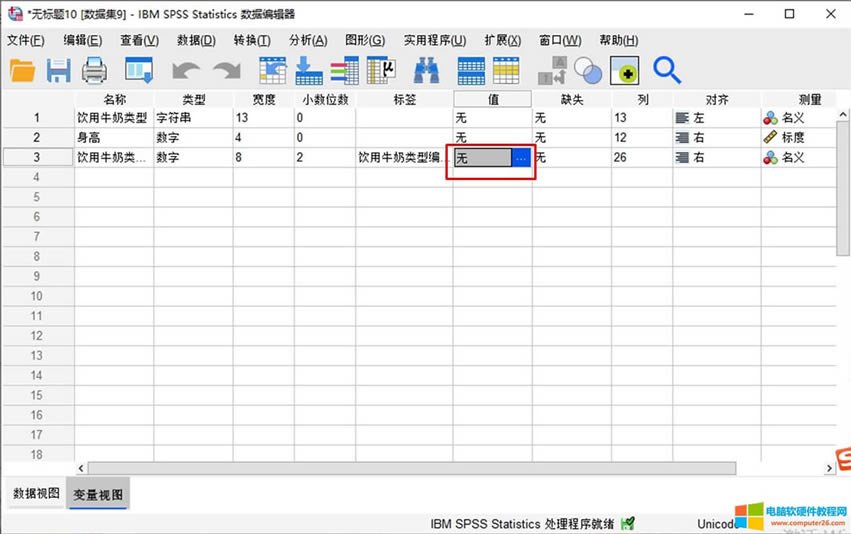
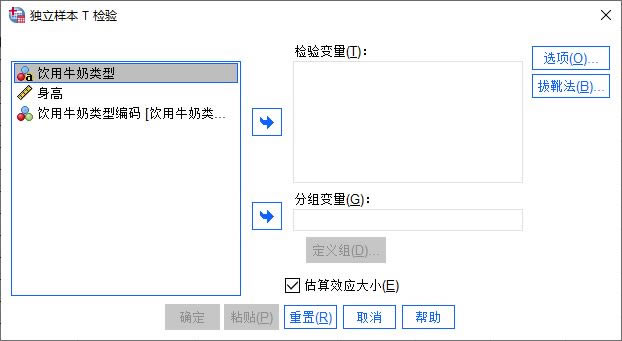
�D5�����׃�������¾��a �������¾��a���׃��ֵ���x�������_����D6��ʾ���҂����Դ��_׃��ҕ�D����׃����ֵ�˺���
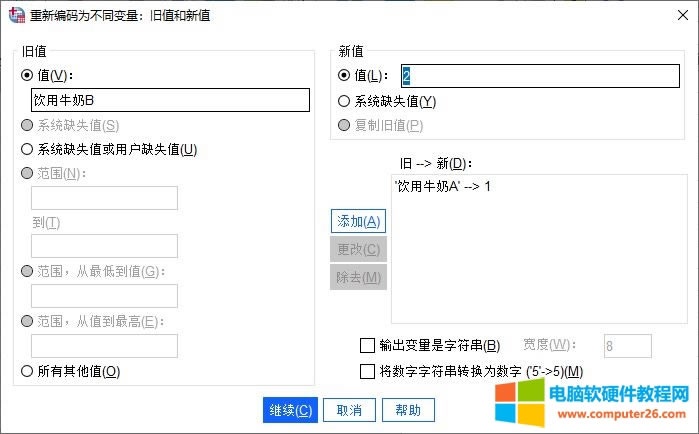
��D7��ʾ����ֵ�˺��O����壬�քe��ֵ1��2�˺������ţ��A�����ţ��B��
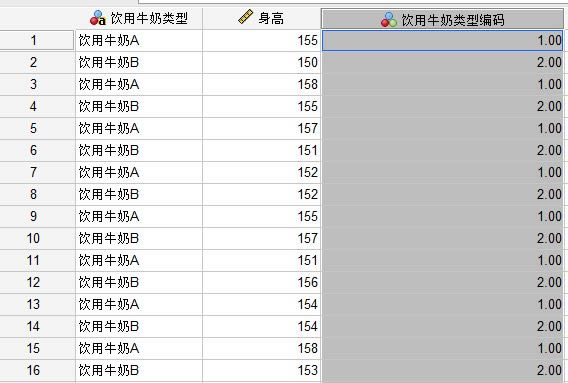
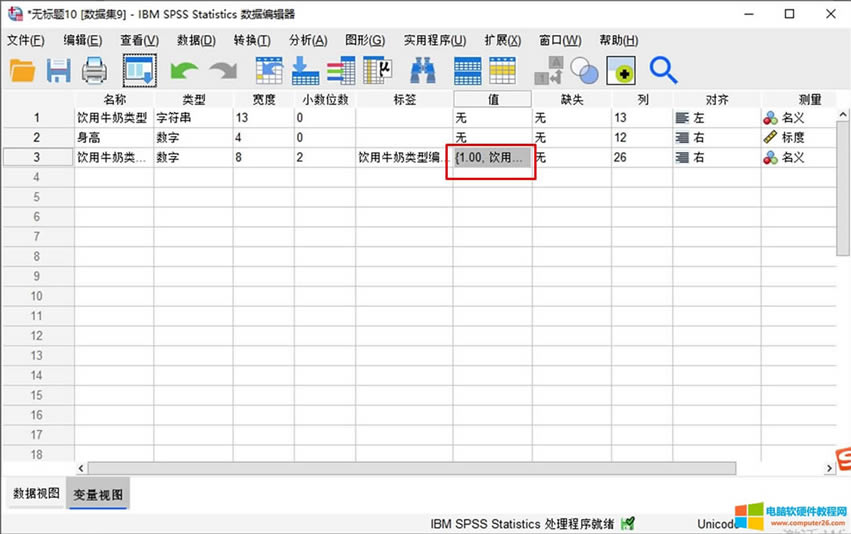
�D7���O���˺� ��D8��ʾ������׃��ҕ�D�����Կ�����ֵ�˺��ѽ�����ɡ�
�������ê����ӱ��z� ��ɔ�����̎���Ϳ��Դ��_IBM SPSS Statistics�Ī����ӱ�T�z�ܣ�����-���^ƽ��ֵ-�����ӱ�T�z����ʽ�_�������ęz
�D9�������ӱ��z�� ��һ�����҂����c�v����IBM SPSS Statistics�����ӱ�T�z�ęz�ԭ��������Ҫ���Լ������D�Q�ķ������@���ֵă����ஔ��Ҫ�����h����������һ�������ٌW�������Č��������� ��D1��ʾ�����Կ����������ӱ�T�z�H�����˙z�׃������ˣ���Ҫʹ�Â����M�����M�Йz����ֽM׃����������R�ɽM����ʹ�õġ��������҂�ͨ�^ʾ�������W���²�����
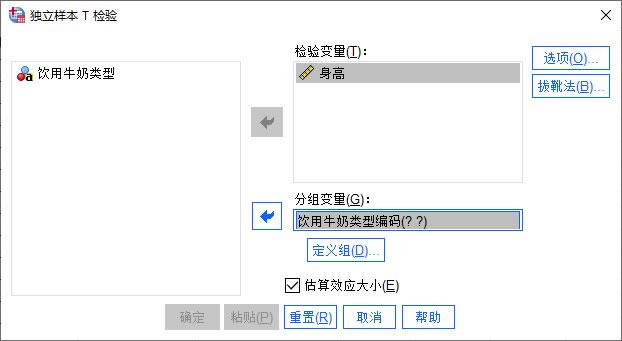
�D1�������ӱ�T�z� һ���x��׃�� ���ȣ��˽����O������е�׃����� 1. �z�׃�������z��ֵ�Ƿ�����@���Բ��׃����ֵ�� 2. �ֽM׃���������ژ��R�ɽM������׃���� �����У��҂���Ҫ�z�������ţ��A�M�c���ţ��B�M��ƽ�����ߔ����Ƿ��в����ˣ���Ҫ������׃�����Ӟ�z�׃���������ţ����;��a���Ӟ�ֽM׃���� Ȼ�Γ����x�M���o��
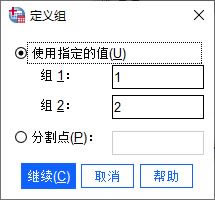
�D2���x��׃�� �������x�M ��D3��ʾ���ڶ��x�M�O����壬��Ҫ�O�Â����M�����ľ��a��ֵ������ǔ�ֵ��ֵ����һ���У��҂��ѽ������ţ�����׃�����¾��a��ֵ1��2����ˣ�����ֱ�ӌ����c�M1��2ƥ�䡣
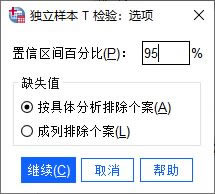
�D3�����x�M �����x��O�� ���������_“�x�”���o���O�Ùz���������Ņ^�g��һ����r�£��O�Þ�95%�ܴ_���^��Ĝʴ_�ԡ�ͬ�r���O��“�����w�����ų�����”��ȱʧֵ̎����ʽ��
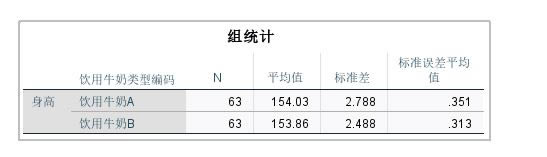
�D4���x��O�� �ġ������Y�����x ��������O�ú��\�з�������D5��ʾ�������зքe����63�����ţ��A�c63�����ţ��B�����ߔ���������ƽ��ֵ���������ţ��A�M�����߾�ֵ�������ţ��B�M�����߾�ֵ�������Ƿ��@��߀Ҫ���@���Ԕ�����
�D5�������yӋ��ֵ ��D6��ʾ���Ī����ӱ��z�D���Ĕ����������@���ԣ��pβ���Ĕ�ֵ0.711����0.05��95%���Ņ^�g�£������ܾܽ^ԭ���O��Ҳ�����f�����ţ��A�M�����߾�ֵ�c���ţ��B�M�����߾�ֵ�o�@���Բ��
���Ͼ���IBM SPSS Statistics�����ӱ�T�z��đ��ý�B��ԓ�������ڱ��^�ɽM�����ľ�ֵ�����������C�ɂ����Ȃ����M�ľ�ֵ��ֵ�Ƿ����@���Բ����������ˎ���о��I����C�ɷNˎ����Ч���Ƿ��в�ȡ� �������S����Ӱ푵Ĉ��s־��SPSS�o���˸߶ȵ��u�r�� |
�������P�I�~�� SPSS�����ӱ�T�z�^��
���P����
��һƪ����Α���SPSS�Θӱ�T�zSPSS�z��
��һƪ��SPSS���ָ���^�ַ���֮�x��
Windowsϵ�y�̳̙�Ŀ
��̳�����
ϵ�y���T�̳�
�����Tϵ�y������