
���h��OCR�e��ٶ��ơ��h��OCR�e��ٶ������d v8.1.5 ��Xpc��

- ܛ����ͣ��D��ܛ��
- ܛ���Z�ԣ����w����
- �ڙʽ�����Mܛ��
- ���r�g��2024-11-15
- ��x������
- ���]�Ǽ�:
- �\�Эh����WinXP,Win7,Win10,Win11
�h��OCR�e��ٶ��ƽ�B
�h��OCR�e��ٶ�����һ�����Ƶ�OCR���ֈD�ߣ�һ���܉�����X��һվʽ�ھ��R�e�����p�Ɍ��D���ϵ����������R�e�����֣��R�e��ʮ�ָߡ��h��OCR�e��ʹ������ʮ�ֵĺ��Σ��Ñ�ֻҪ���D����_���R�e����������ĵ�Ԓ���͕��Ԅӷ��g�����ģ������Ñ���ʹ�á�
�h��OCR�e����ɫ
�h��PDF OCR�R�e���_�ʸߣ��R�e�ٶȿ졢����̎������
֧��̎���Ҷȡ���ɫ���ڰ����Nɫ�ʵ�BMP��TIF��JPG��PDF��N��ʽ�ĈD���ļ�;
�h��PDF OCR���R�e���w�����w��Ӣ�����N�Z��;
�h��PDF OCR���к������õı����R�e����;
����TXT��RTF��HTM��XLS��Nݔ����ʽ��������Ҋ�����õİ���߀ԭ���ܡ�
�h��OCR���M�R�e����
1�������҂����_����X�ϰ��b�õĝh��PDF OCRܛ����Ȼ��Ϳ����M�뵽ܛ���������棬���D��ʾ���҂��������c���ļ��x헣�Ȼ������F�������҂��x���c��“���_�D��”�x헣�����Կ���ֱ��ʹ�ô��_�^��Ŀ���I������ICtrl+O��
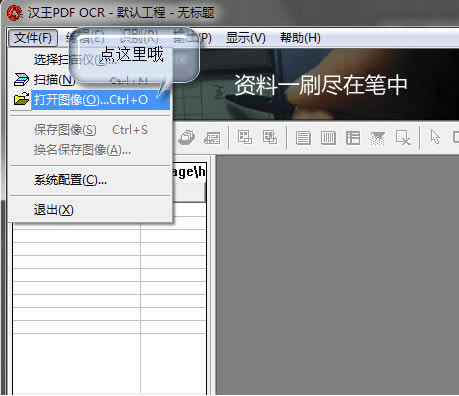
2�������҂��͕��M�뵽���_�^���ļ����棬���D��ʾ���҂���Ҫ�ҵ�������X�ϵ�PDF�ļ����ҵ����҂��c��PDF�ļ��x�����������c������·���“PDF�D�Q��TXT�ļ�”�x헣�Ȼ���M����һ�����@����Ҫע����Dz�Ҫ�c�������е�“���_”�x헡�
3��Ȼ���҂����M�뵽PDF�D�Q��TXT���棬���D��ʾ���҂��ڽ������x���D�Q����棬������x���D�Q�ķ������ĵڎ���_ʼ���ڎ�퓽Y�����x����ɺ��҂��ڽ�����·�߀��Ҫ�x��Ŀ䛣��c���g�[�x����m��λ�ú����c���_����
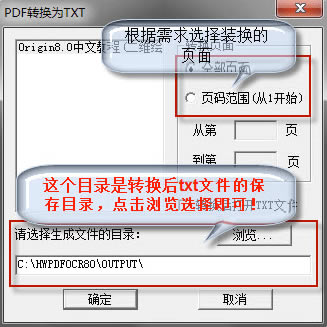
4���ȴ��D�Q��ɺ��҂��Ϳ������O�õı���λ���ҵ��D�Q��ɺ��TXT�ļ��ˡ��D�Q�ĕr�g�Ǹ������D�Q�Ĕ�����Q���ģ������٣��D�Q�죬�����࣬�D�Q�ľͱ��^����
�h��ocr��ô�D�Qexcel
1���h��OCR�����ļ����R�e�ļ��е����֣���ݔ����TXT�ļ���
2�����_ԓTXT�ļ����������M���Ű棨�������ķָ����������õķָ���Ҳ�����ո��Ʊ�����Ӣ�ĵĶ�̖�Լ���̖�ķN����
3��������еķָ����������@ƪ�ęn��
4����Excelܛ�����_һƪ�հ�������
5���ГQ��“����”�x헿����Γ�“�@ȡ�ⲿ����”�M�е�“���ı�”���
6���ڏ���“�����ı��ļ�”���ڣ��x����Ҫ�����TXT�ļ����Γ��룻
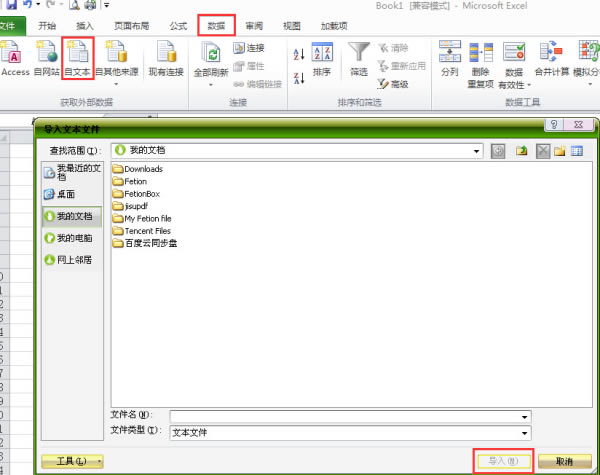
7���ڏ�����“�ı������� - ��1������3��”��Ԓ���У��x��Ĭ�Jԭʼ������ͣ�“��һ��”��
8���ڏ�����“�ı������� - ��2������3��”��Ԓ���x���п��õķָ���̖��“��һ��”��
9���ڏ�����“�ı������� - ��3������3��”��Ԓ���У��x��Ĭ�J�Д�����ʽ��“���”��
10���ڏ���һ��“���딵��”��Ԓ���x���ķ���λ�ã����ɡ�
�h��ocr����R�e
��һ�������_�҂����d�õ�ܛ���������Fһ����Ԓ���x�������“�ĈDƬ���x�ļ�”��Ȼ���ڌ�Ԓ���У����_��Ҫ���ĈDƬ��
�ڶ������DƬ�͕����F�ھ�������ˡ��@�r�҂��c�������“�������”��ܛ���͕��Ԅӌ��ļ��M�зֽ��Ű棬�Ա��ں��m���R�e�^�̡�
���������c�������“�R�e”���o��ܛ���͕��Ԅӌ��ļ��ϵ������M���R�e����һ�����͕����R�e�Y���ʬF����߅����ҿ��Ԍ��R�e�Y���M��У��������l�F�e�`�����M�и���������Ƕ�퓃����M���R�e��Ԓ���҂������c���R�e���o�x���·���“ȫ��”�����܌����Ѓ����M���R�e�ˡ����ֻ�댦����M���R�e��Ԓ��ֻҪ�x��ԓ��M���R�e�Ϳ����ˡ�
���IJ�������҂���Ҫ�����Word��ʽ��Ԓ��ֱ���c���Ϸ���“Word”���o���x��ݔ��·���Ϳ�������ˡ���ȻҲ���Ա����DƬ��ʽ��ֻҪ�c���Ϸ���“�DƬ”���o���ɡ�
�h��ocr����I
�����ļ��� ����“Ctrl+N”�{�����������D���ļ���
���_�ļ��� ����“Ctrl+O”���_�D���ļ����ӈD���ļ���
����D�� ����“Ctrl+S”�I����D��
�D�ף� ����“Ctrl+I”���D�ס�
�ԄӃAбУ���� ����“Ctrl+D”�M���ԄӃAбУ����
�քӃAбУ���� ����“Ctrl+M”�M���քӃAбУ����
��������� ����“F5”�I�����x�е��ļ��M�а��������
ȡ����������� ����“Ctrl+Del”�I��ȡ����ǰ퓵İ��������
1�M���ƽ̌Wͨ2.0-�M���ƽ̌Wͨ2.0���d v5......
2step7 microwin-���T��PLC S7......
3�ٶȾW�P��ˬ����������-�W�P����-�ٶȾW�P��ˬ��......
4360��ȫ�g�[��-�g�[��-360��ȫ�g�[�����d ......
5�ȸ�g�[�� XP��-�ȸ�g�[�� XP��-�ȸ�g�[......
6Kittenblock�ؑc�������ð�-�C���˾���......
7seo�������(�������) -SEO��會�������......
8Notepad3-ӛ�±�ܛ��-Notepad3��......