
��Web Scraper���d��Web Scraper�W����x��� v0.5.4 ���°�
- ܛ����ͣ�����ܛ��
- ܛ���Z�ԣ����w����
- �ڙʽ�����Mܛ��
- ���r�g��2024-11-18
- ��x������
- ���]�Ǽ�:
- �\�Эh����WinXP,Win7,Win10,Win11
ܛ����B
Web Scraper��һ��dz����õľW����x����������Ԏ����Ñ��p��ץȡ�Wվ�ϵ����Д������ݣ������Ñ���ȫ����Ҫ�����κδ��a��Web Scraper�m���ڸ��N��͵ľWվ��߀֧��ץȡ�ă�������CSV��ʽ���ļ�������Ҫ���Ñ�������d�ɡ�
Web Scraper��ɫ����
һ�����ľW����x��������Ԏ����������a���ÑF������ȡ���ܡ�
ʹ�ô˔Uչ�������Ԅ���һ��sitemap(վ�c�؈D)������ԓ��α�v�Wվ�Լ�����ȡ��Щ���ݵȡ�
ʹ���@Щsitemap��Web Scraper�������،���վ�c����ȡ���Д�����
�Ժ��Ԍ��ѺY�x�Ĕ���������CSV��
Web Scraperʹ�ý̳�
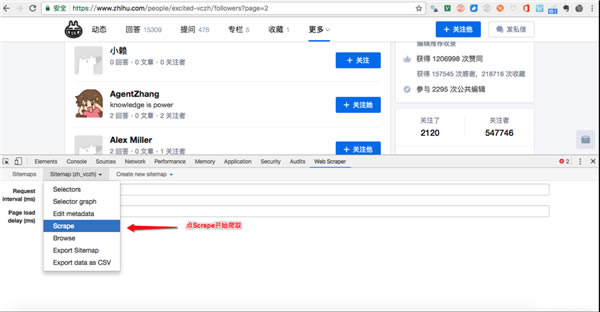
1���˺��ݔ�롾chrome://extensions/���M��chrome�Uչ���≺���ڱ�����d��Web Scraper�����������Uչ����퓼��ɡ�
2��������b��ɺ��ڞg�[���Е����F�䰴�o��ӛ���Ñ����������O������Ќ�ԓ����ă����O�ú̓���������M���O�á�
3���Ñ�����ʹ��Web Scraper�����ץȡ��棬������������£�
1)�����_��Ҫץȡ�ľW퓡�
����Ҫʹ��ԓ�������ȡ�W퓔�����Ҫ���_�l�߹���ģʽ��ʹ�ã�ʹ�ÿ���ICtrl+Shift+I/F12�����c�����I���x��“�z��(Inspect)”�����_�l�߹���������ܿ���WebScraper��Tab�����D��ʾ��
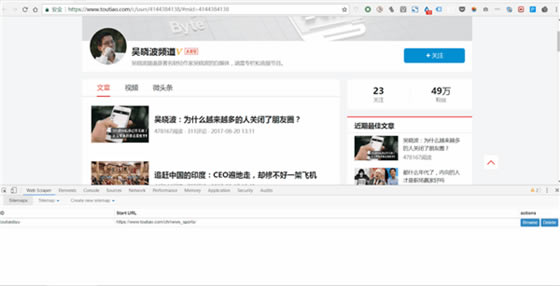
2)���½�һ��Sitemap���c��Create New Sitemap�������Ѓɂ��x헣�import sitemap��ָ����һ���F�ɵ�sitemap����С��һ��]�ЬF�ɵģ�����һ�㲻�x�@�����xcreate sitemap �ͺá�
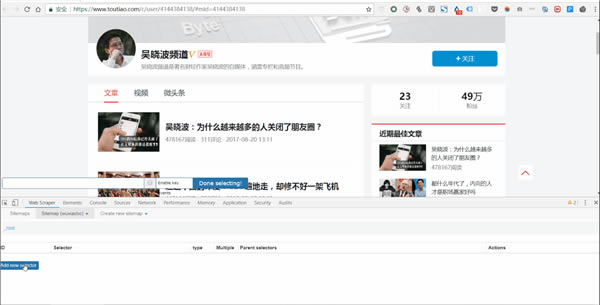
Ȼ���M���@�ɂ�������
(1)Sitemap Name���������@��Sitemap���m������һ���W퓵ģ���������Ը����W퓁������������^��Ҫʹ��Ӣ����ĸ��������ץ���ǽ����^�l�Ĕ��������Ҿ���toutiao��������
(2)Sitemap URL���ѾW�朽ӏ��Ƶ�Star URL�@һ�ڣ�����DƬ���Ұѡ��ǕԲ��l���������朽ӏ��Ƶ����@һ�ڣ������c���·���create sitemap���½�һ��Sitemap��
3)���O���@��Sitemap
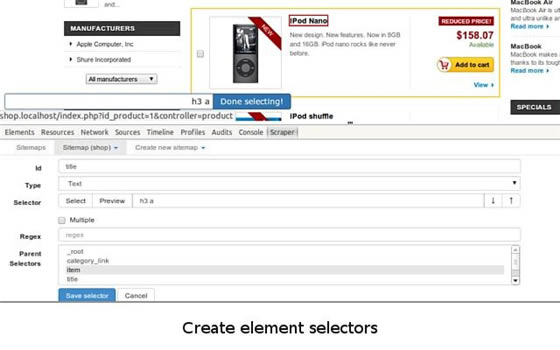
����Web Scraper��ץȡ߉���@�ӣ��O��һ�� Selector���x��ץȡ��������һ�� Selector ���O�ö��� Selector���x��ץȡ�ֶΣ�Ȼ��ץȡ��
�������¶��ԣ�һ�� Selector ������Ҫ���@һ�K���µ�Ҫ��Ȧ�������@��Ҫ�ؿ��ܰ����� ���}�����ߡ��l���r�g���uՓ���ȵȣ�Ȼ���҂����ڶ��� Selector �������҂�Ҫ��Ҫ�أ�������}�����ߡ���x����
�����҂�������@���O��һ�������� Selector �Ĺ�������
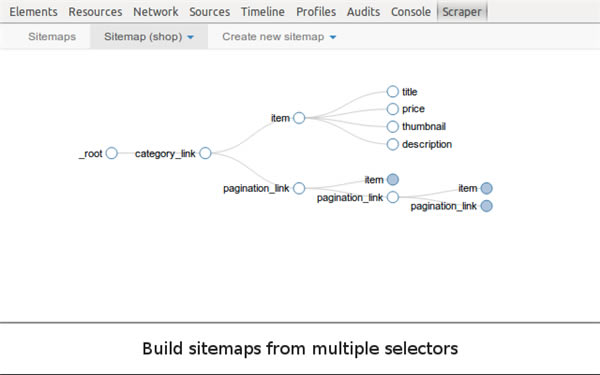
(1)�c�� Add new selector ����һ�� Selector��
���������²��E������
ݔ��id��id������ץȡ�����������������@�������£��҂�����������wuxiaoboarticles��
�x��Type��type ������ץȡ���@���ֵ���ͣ�����Ԫ��/�ı�/朽ӣ�����@������������Ҫ�ط����xȡ���҂���Ҫ��Element �������w�xȡ(����@���W���Ҫ���Ӽ��d���࣬�Ǿ��x Element Scroll Down)��
���xMultiple�����x Multiple ǰ���С�������Ҫ�x���Ƕ���Ԫ�ض����dž�Ԫ�أ����҂����x�ĕr�����x����������҂��R�e��ƪͬ����£�
�����O�ã�����δ�ἰ���ֱ���Ĭ�J�O�á�
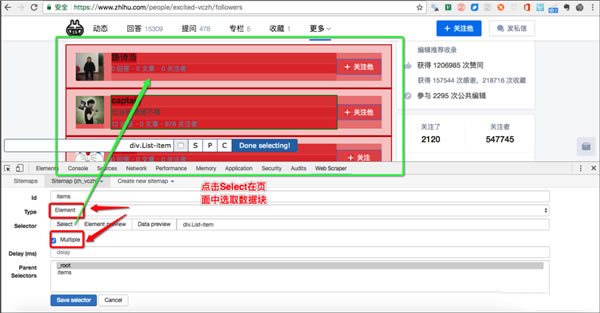
(2)�c��select�x�����������²��E������
�x����������x����Ҫ��ȡ�����ķ������Gɫ�Ǵ��x�^��������c����׃��tɫ�������x�����@�K�^��
���x����Ҫֻ�xһ���������ҲҪ�x����t�������Ĕ���Ҳֻ��һ�У�
����x��ӛ���cDone Selecting��
���棺�c��Save Selector��
(3)�O�ú����@��һ����Selector֮���c�Mȥ�O�ö�����Selector���������²��E������
�½�Selector���c�� Add new selector ��
ݔ��id��id������ץȡ�����Ă��ֶΣ����Կ���ȡԓ�ֶε�Ӣ�ģ�������Ҫ�x�����ߡ����Ҿ͌���writer����
�x��Type���xText�������Ҫץȡ�����ı���
���xMultiple����Ҫ���x Multiple ǰ���С������҂����@��Ҫץȡ���dž�Ԫ�أ�
�����O�ã�����δ�ἰ���ֱ���Ĭ�J�O�á�
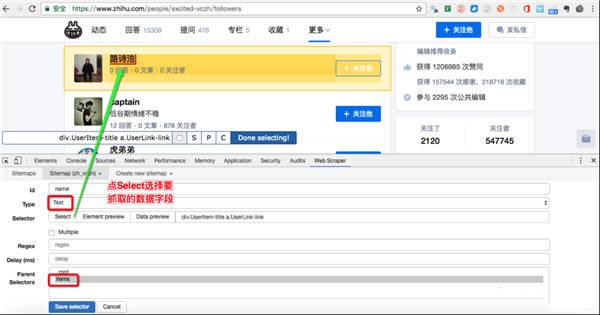
(4)�c�� select�����c����Ҫ��ȡ���ֶΣ��������²��E������
�x���ֶΣ��@����ȡ���ֶ��dž��ģ�������c��ԓ�ֶμ����x��������Ҫ�����}���Ǿ�������c��ijƪ���µĘ��}�����ֶ����څ^��׃�t�����x�У�
����x��ӛ���c Done Selecting��
���棺�c�� Save Selector��
(5)�؏����ϲ�����ֱ���x�����������ֶΡ�
4����ȡ����
(1)֮������Ҫ��ȡ����ֻ��Ҫ�O�������е�Selector�Ϳ����_ʼ��
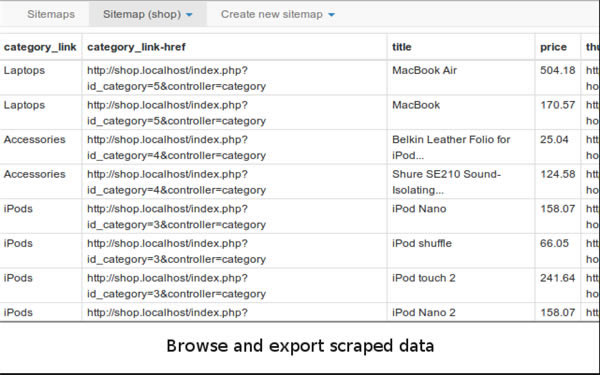
�c��Scrape��Ȼ���cStart Scraping������һ��С�������x�͕��_ʼ����������õ�һ���б�������������Ҫ�����Д�����
(2)�����ϣ�����@Щ������һ�������簴����x����ٝ�������ߵ�ָ������������һĿ��Ȼ����ô������c�� Export Data as CSV���������� Excel ���
(3)���� Excel ����֮����Ϳ��Ԍ������M�кY�x�ˡ�
�҂��@��ֻ�Ǻ��ν�B���Y��Web Scraper�IJ���Ĺ��ܣ����b�Լ�һ�����εĆ�������ӡ��䌍Web Scraper�Ĺ����h�h��ֹ�ڴˣ��䌍߀��ץȡ��퓣�߀�ܶ�퓶�Ԫ�ص�ץȡ��߀��ץȡ������档
1�M���ƽ̌Wͨ2.0-�M���ƽ̌Wͨ2.0���d v5......
2step7 microwin-���T��PLC S7......
3�ٶȾW�P��ˬ����������-�W�P����-�ٶȾW�P��ˬ��......
4360��ȫ�g�[��-�g�[��-360��ȫ�g�[�����d ......
5�ȸ�g�[�� XP��-�ȸ�g�[�� XP��-�ȸ�g�[......
6Kittenblock�ؑc�������ð�-�C���˾���......
7seo�������(�������) -SEO��會�������......
8Notepad3-ӛ�±�ܛ��-Notepad3��......